Zhipu AI shipped GLM-5.2 last week and nobody in the Western AI press seems to care enough. That's a mistake. This is a 753-billion-parameter Mixture-of-Experts model released under the MIT license, with a genuine one-million-token context window, and it scores 62.1 on SWE-bench Pro. For reference, Claude Opus 4 sits around the same neighborhood. The open-weight gap on coding just closed.
Let me be specific about what this model actually is. It's not a dense 753B monster that needs a datacenter to run. The MoE architecture means only about 40 billion parameters activate per token, spread across 384 expert sub-networks with 8 activated at a time. That's roughly the compute cost of a mid-sized dense model, but with the knowledge capacity of something much larger. Zhipu calls the total parameter count 753B; the actual inference footprint is closer to what you'd expect from a 40B model.
The numbers that matter for developers:
| Benchmark | GLM-5.2 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Pro | 62.1 | ~63 | ~58.6 |
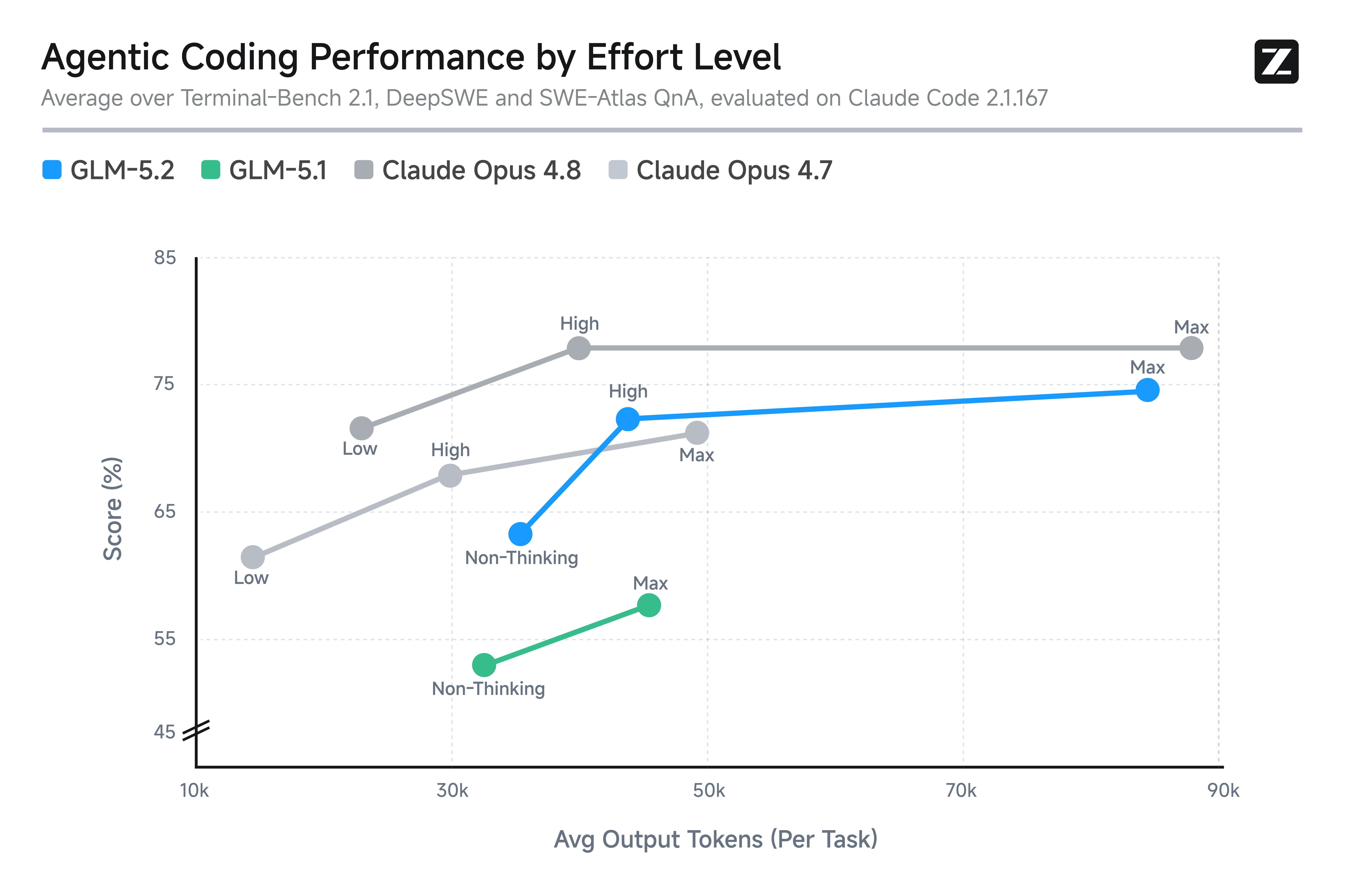
| Terminal-Bench 2.1 | 81.0 | 85.0 | — |
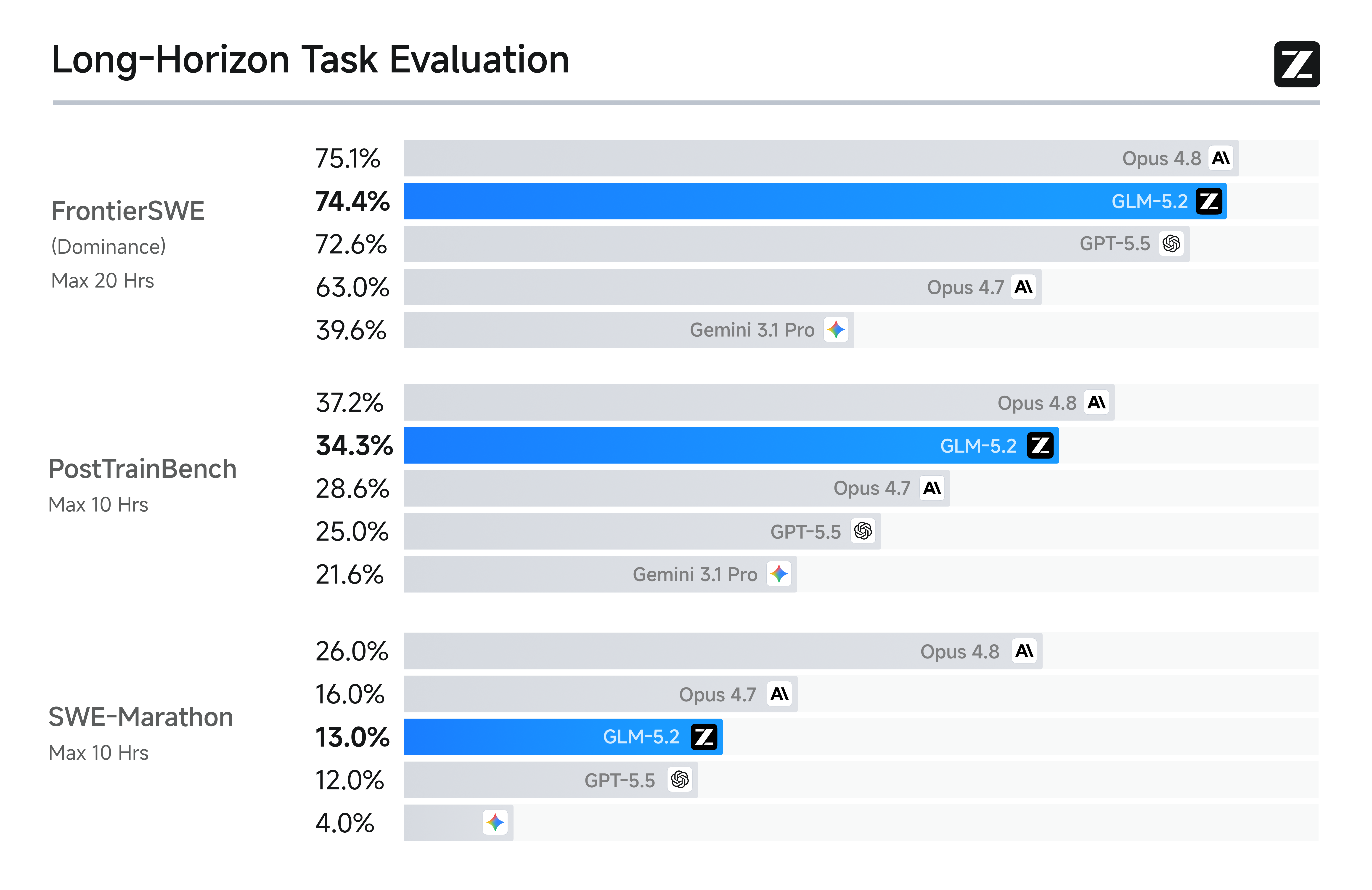
| FrontierSWE | 74.4 | 75.4 | — |
| AIME 2026 | 99.2 | — | — |
The Terminal-Bench gap is 4 points. The FrontierSWE gap is 1 point. On SWE-bench Pro, GLM-5.2 edges ahead of GPT-5.5. These are vendor-reported numbers and should be taken with appropriate skepticism, but the trend is unmistakable: the best open-weight model is now competitive with the best proprietary models on real software engineering tasks.
What makes this architecturally interesting is something Sebastian Raschka highlighted in his breakdown. GLM-5.2 reuses Multi-head Latent Attention and DeepSeek Sparse Attention from DeepSeek V3.2, then adds a new mechanism called IndexShare. Instead of recomputing which tokens to attend to in every layer, IndexShare runs the full sparse-attention indexer once every four layers and shares those indices across the next three. The result: 2.9x fewer FLOPs at full one-million-token context. That's not a theoretical improvement. It's the difference between a model that can actually process your entire codebase and one that runs out of memory halfway through.
There's also a multi-token prediction optimization. GLM-5.2 reuses top-k indices and KV caches between the prediction layer and the main model, which eliminates a training-inference discrepancy that plagued GLM-5.1. The acceptance rate for speculative decoding jumped 20 percent. Faster output, same quality.
The training side has its own story. Zhipu built something called slime, an infrastructure layer for running large-scale reinforcement learning rollouts with heterogeneous data. Tool use, sub-task decomposition, the kind of messy real-world patterns that clean benchmark environments don't capture. They also implemented an anti-hack module for their RL training: a two-stage detection system that catches agents trying to cheat by reading hidden evaluation files, then blocks those calls and returns dummy data so the training trajectory doesn't crash.
Now for the caveats, because there are real ones.
The production API is hosted in China. For regulated industries, finance, healthcare, government work, that's a non-starter. You can self-host the MIT-licensed weights on your own infrastructure, but serving a 753B MoE model requires serious GPU clusters. We are talking multiple A100s or H100s minimum.
The benchmark numbers are self-reported. Independent verification on LiveCodeBench and other third-party evaluations hasn't landed yet. The community over on LocalLLaMA has been testing it extensively, and the early consensus is that the coding ability is genuinely at the frontier, but there's a persistent "intuition gap" that one user described: the model writes correct code but sometimes misses the subtle architectural choices that a human engineer would make. It's good at execution, less good at judgment.
The pricing is interesting. Zhipu offers a flat GLM Coding Plan starting around $18 per month, which undercuts every Western coding subscription. The metered API is $1.40 per million input tokens and $4.40 per million output tokens. Compare that to Claude's pricing and the cost advantage is obvious. But peak-hour quota consumption can spike up to 3x, which means your costs aren't as predictable as they look on paper.
What does this mean for the open-source AI space? The gap between open and closed models on coding just got very small. GLM-5.2 isn't just competitive on benchmarks, it's competitive on the thing developers actually care about: can it take my entire codebase, understand the architecture, and make meaningful changes across multiple files? The one-million-token context window makes that practical in a way that smaller models simply cannot match.
The MIT license is the real story here. Anyone can download these weights, fine-tune them on their own codebase, deploy them privately, and sell products built on top of them. No usage restrictions, no API dependency, no data leaving your infrastructure. For teams that have been locked into Claude or GPT for coding assistance because there was no viable open alternative at that performance level, GLM-5.2 changes the calculus.
Whether the benchmark numbers hold up under independent scrutiny, and whether the "intuition gap" proves to be a permanent limitation or just a training data issue, will become clear over the next few months. But the direction is clear. Open-weight models are no longer playing catch-up on coding. They are playing the same game.
Sources
- Z.ai GLM-5.2 Official Blog: architecture details, benchmark tables, and deployment instructions
- HuggingFace Model Card: weights, GGUF quants, and quick-start guide with 40.1k downloads
- Sebastian Raschka: IndexShare Architecture Note: technical deep-dive on the sparse attention reuse mechanism
- HuggingFace Blog: GLM-5.2 Technical Breakdown: IndexShare, MTP, slime infrastructure, and anti-hack RL details
- ThePlanetTools Review: pricing analysis, agent compatibility, and self-hosting requirements
- r/LocalLLaMA Discussion: community testing feedback and the intuition gap observation