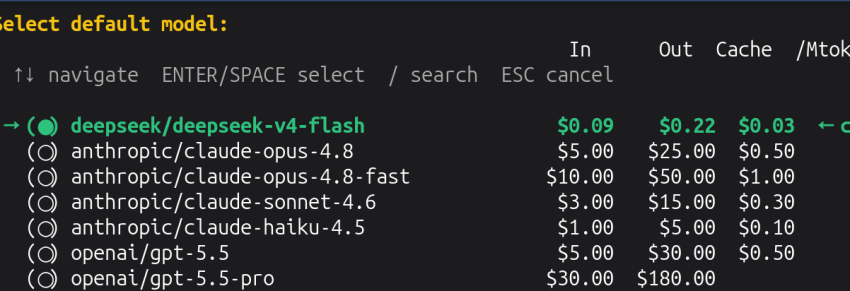
Two numbers stopped me mid-scroll this morning. DeepSeek V4 Flash charges $0.14 per million input tokens. Claude Opus 4.8 charges $5.00. That's not a rounding error. That's a 35x gap for models that score within single digits of each other on most benchmarks.
James O'Claire wrote about this today on his blog, and the HN thread blew up to 122 points in hours. The core question is uncomfortable: if open-weight models can do 95% of what you're paying top dollar for, what exactly are you paying for?
The pricing tables tell the story better than any opinion piece. GPT-5.5-pro sits at $180 per million output tokens. Claude Fable 5 at $50. DeepSeek V4 Flash at $0.28. A developer running agentic loops that consume 10 million tokens per day would pay $1,800 on OpenAI's pro tier, $500 on Claude, or $2.80 on DeepSeek. For the same task. With comparable quality on coding and reasoning benchmarks.
This isn't a fluke or a temporary subsidy. The Chinese open-weight models have structurally lower costs because they were built on cheaper infrastructure, optimized by thousands of community contributors stress-testing on different hardware, and priced to grab market share. But here's the thing: they actually work. An HN commenter put it plainly: "Ever since I moved to DeepSeek I had zero regrets. It performs exceptionally well. I honestly prefer it to ChatGPT."
The economics get stranger when you factor in caching. DeepSeek has a 0.02x multiplier on cached inputs. Anthropic does 0.1x. One developer in the thread reported doing a month of work for under $2 using harnesses that exploit cache hit rates. That's not competing on price anymore. That's a completely different game.
OpenAI and Anthropic have three real options, and none of them are comfortable. First, they can slash prices by 20-50x to match open-weight competitors. This seems unlikely given their reported burn rates and the capital intensity of training frontier models. Second, they can retreat into luxury positioning, the way high-end car brands sell exclusivity rather than transportation. Claude's gated previews, OpenAI's pro tiers, and Anthropic's refusal to release open weights all point in this direction. Third, and this is the one that worries people, they can push for regulatory restrictions on open-weight models, particularly those from Chinese labs.
That third option isn't paranoid. The US NSF partnered with Nvidia to fund Allen AI's OMO project specifically to create a "true fully open" American alternative. The subtext is clear: if you can't beat the cheap Chinese models on price, create a politically acceptable American version and use national security framing to restrict the competition.
The benchmark reality makes this even more urgent. GLM 5.1, an open-weight model from Zhipu AI, scored 58.4 on SWE-Bench Pro. GPT-5.4 scored 57.7. Claude Opus 4.6 scored 57.3. An open-weight model that anyone can download just outperformed the two most expensive closed APIs in the world. Kimi K2.6 from Moonshot AI, with its trillion-parameter MoE architecture, runs inference at the cost of a 32B dense model while matching frontier performance.
What makes the open-weight advantage structural rather than temporary is the community optimization loop. When you release model weights publicly, thousands of people figure out how to run them more efficiently. They discover quantization tricks, inference optimizations, and deployment patterns that the original creators never anticipated. This drives costs down continuously in a way that proprietary models, locked behind API walls, simply cannot match.
For most developers, the practical calculation is brutal. Do you need the absolute best model for a specific task, or do you need a model that's 95% as good at 3% of the cost? For coding, research, and most agentic workflows, the answer is increasingly the latter. The "nobody gets fired for buying IBM" instinct that keeps people on expensive APIs is a luxury that fewer teams can justify.
The real wild card is what happens when this pricing pressure reaches enterprise procurement. Right now, companies pay premium API prices partly because they want contracts, SLAs, and someone to call when things break. Open-weight models require hosting your own infrastructure or using third-party providers. But providers like Cloudflare and Digital Ocean already host the same models at similar pricing to the Chinese labs. The gap between "easy to buy" and "cheap to run" is closing fast.
Allen AI's OMO project might be the most interesting long-term play. It's not just open weights, it's an open training pipeline. You can see exactly what data went into the model, how it was trained, and reproduce it yourself. That's a level of transparency that even the most generous open-weight releases don't offer. If OMO catches up on quality, it removes the last argument for paying premium prices: trust.
The uncomfortable truth buried in all these numbers is that the AI industry's pricing model was always built on scarcity that may not exist. When intelligence becomes a commodity that costs pennies per million tokens, the companies built on charging dollars per token have a structural problem. The question isn't whether prices will fall. It's whether the incumbents can adapt before the floor drops out.