Vision models finally broke free from the token-by-token cage
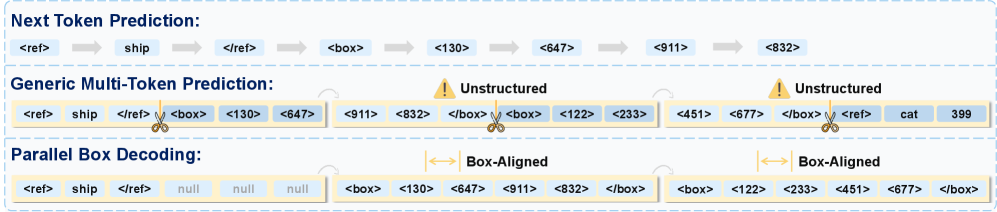
There is a quiet bottleneck in every vision-language model that nobody talks about enough. When you ask a VLM to find an object in an image. A pedestrian, a button in a UI, a specific car. It does not see the box all at once. It guesses one coordinate at a time. x1, then y1, then x2, then y2, one token after another, like a person drawing a rectangle by moving the pencil one millimeter at a time instead of just placing four corners. That sequential token generation adds real latency, and in robotics, autonomous driving, or even GUI automation, latency is the difference between reacting and crashing. NVIDIA just published a method that eliminates this bottleneck entirely.
How Parallel Box Decoding Works
The core idea is almost too simple. Instead of serializing a bounding box into four sequential tokens, LocateAnything treats each box as an atomic unit. The model predicts all four coordinates in a single parallel step. This is called Parallel Box Decoding, or PBD.
The architecture pairs a Moon-ViT vision encoder (preserves native resolution, no resolution downscaling) with a Qwen2.5 language decoder. The key training trick is dual-formulation: the model trains on both standard Next-Token Prediction (NTP) to preserve causal reasoning and block-level Multi-Token Prediction (MTP) for parallel efficiency. An attention mechanism called Block-Causal Flow ensures dependencies between boxes are learned without future-token leakage, while Bidirectional Intra-Block Attention lets tokens within a single box interact to capture geometric structure.
Benchmark Results
The numbers are striking. LocateAnything achieves 12.7 Boxes Per Second (BPS) in Hybrid mode on an H100. Compare that to 1.1 BPS for standard VLMs like Qwen3-VL and 5.0 BPS for previous specialized models like Rex-Omni. That is roughly 10x faster than the baseline.
Throughput comparison:
| Mode | Boxes/sec | Best use case |
|---|---|---|
| Fast (MTP only) | 15.3 BPS | Robotics, real-time |
| Hybrid (default) | 12.7 BPS | Production pipelines |
| Slow (autoregressive) | 4.3 BPS | High-precision labeling |
Accuracy did not suffer for the speedup. On LVIS, LocateAnything gains +3.8% mean F1 over prior SOTA. On COCO, +1.8%. The largest gains appear at high IoU thresholds where precision matters most: 31.1 vs 20.7 at IoU=0.95 on LVIS. On GUI grounding (ScreenSpot-Pro), it hits 60.3 F1. On document layout (DocLayNet), 76.8 F1.
The model also comes with a detection mode for dense scenes. It reaches 39.9 mean F1 on VisDrone and 58.7 on Dense200, handling crowded overlapping environments better than anything in its weight class.
Training Data Scale
LocateAnything's strong performance is not just the architecture. The team built a massive training corpus called LocateAnything-Data: 12 million unique images, 138 million natural language queries, and 785 million annotated bounding boxes. The dataset covers general object detection (66.9% of queries), UI grounding (16.5%), referring comprehension (7.3%), text localization (3.6%), layout grounding (3.5%), and point-based localization (2.2%). It explicitly includes negative samples (queries for objects not present in the image) to reduce hallucinations.
The Hybrid Inference Strategy
The cleverest part of the design is the hybrid mode. The model defaults to fast parallel decoding, but it monitors two signals: top-1 coordinate token probability (triggers fallback if below 0.7) and max-min difference among top-5 tokens (triggers if above 80 in a 0-1000 coordinate space). When either signal fires, the model reverts to autoregressive decoding for that specific box. This means simple scenes get the full speed boost, while ambiguous ones get the precision of sequential reasoning.
Architecture Details
The model uses Stream Packing to maximize GPU utilization for variable-length sequences and MagiAttention for efficient handling of heterogeneous attention masks. Both are available as open-source tools. The training pipeline ran on NVIDIA H100 clusters.
The 3B parameter model is available on Hugging Face under a non-commercial research license, and the code lives in the NVlabs/Eagle repository on GitHub. It supports object detection, referring expression grounding, GUI element grounding, text localization, and point-based localization from a single checkpoint.
What Surprised Me
I keep coming back to the throughput number. 12.7 boxes per second in hybrid mode. That is fast enough for a robot to process a live camera feed in real time while the model runs in parallel with other perception tasks. The prior art's 1.1 BPS was a real wall for deployment. You could not use VLMs for online perception without significant engineering workarounds like frame skipping or sliding window heuristics.
The second surprise is that the accuracy improvement is real at high IoU. A lot of vision papers trade speed for precision. PBD does the opposite. The 3.8-point gain on LVIS at the high end suggests that parallel decoding is not just a throughput hack but actually preserves the spatial geometry of boxes better than coordinate serialization. The model understands that x1, y1, x2, y2 belong together because it learns them together.
The non-commercial license is a bummer for production deployments, especially since the training data pipeline (LocateAnything-Data with 785M boxes) is the real moat here. But the ideas (PBD, hybrid inference, dual-formulation training) are reusable in any VLM architecture. I expect to see these techniques absorbed into the next generation of open models within months.