I spent $47 last week on Claude Code tokens. About half of that went to reading files the agent never used. It would grep for a function name, load three files that matched, then decide two were irrelevant and move on. I had already paid for those reads.
There is a name for this: the "dump-and-pray" approach to context management. You shove as many files as possible into the context window and hope the model finds what it needs. With 200K, 500K, even 1M-token context windows, it does not help. The model still loses the plot. It just loses the plot more expensively.
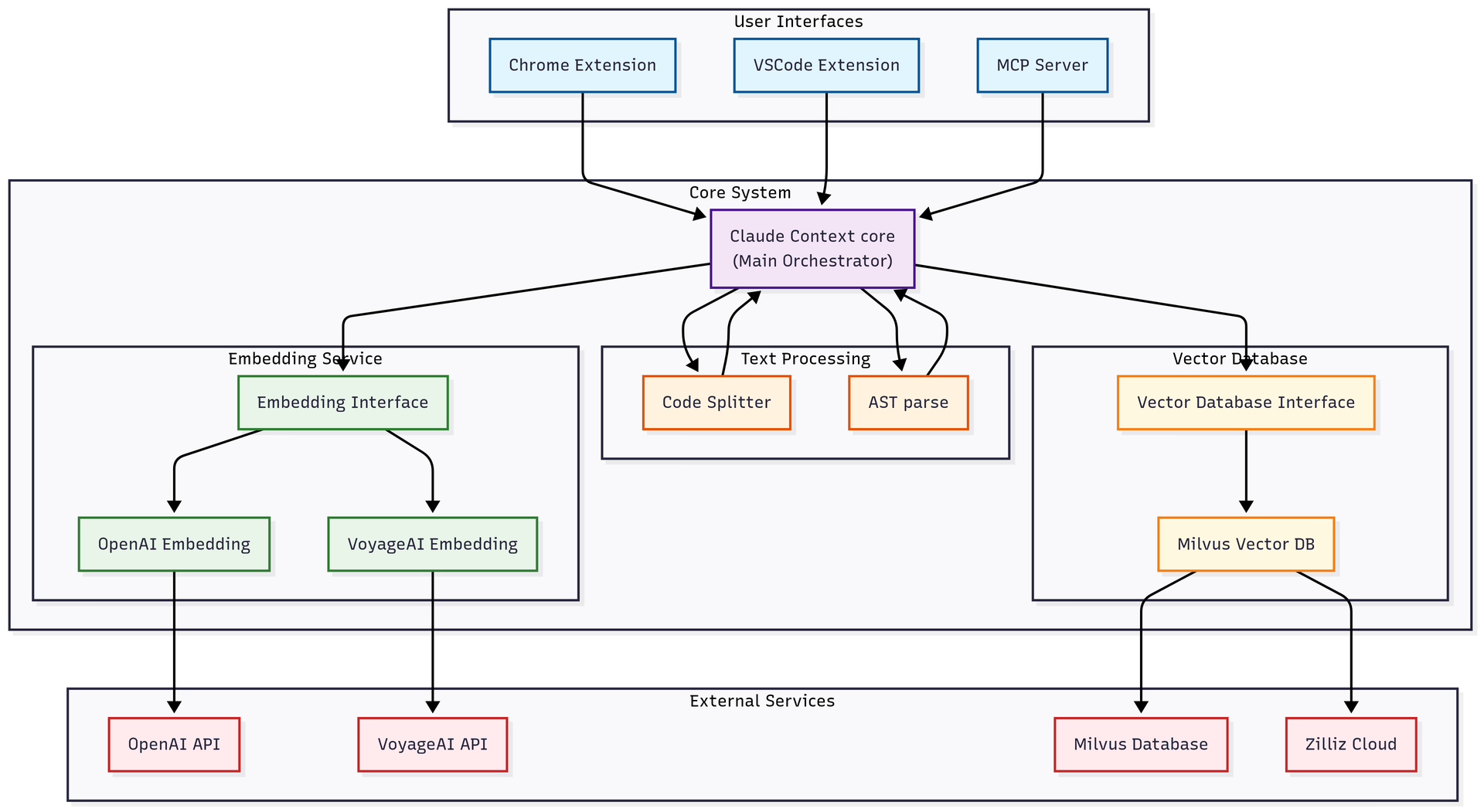
Claude Context is an open-source MCP server from Zilliz (the Milvus team) that fixes the retrieval step. Instead of loading entire directories, it indexes your codebase into a vector database and returns only the 3-5 most relevant code snippets when the agent asks a question. It hit #1 on GitHub Trending this week with nearly 10,000 stars and 3,700 stars gained in seven days.
How It Works
The architecture is straightforward. You point it at a repository, it chunks the code along syntax boundaries (not line counts. It uses AST parsing via tree-sitter to split at function and class boundaries), embeds each chunk into a vector, and stores everything in Milvus (self-hosted or Zilliz Cloud). When the agent needs to find something, it runs a hybrid search: BM25 keyword matching plus dense vector similarity. The result is the top 3-5 chunks, injected directly into the agent's context.
Key numbers from the project benchmarks:
| Metric | Value |
|---|---|
| Token reduction vs. full-context loading | ~40% |
| Star count (May 24, 2026) | ~10,000 |
| Stars gained this week | +3,725 |
| GitHub trending rank | #1 |
| Compatible clients | 13+ (Claude Code, Cursor, Codex CLI, Windsurf, Cline, etc.) |
| Embedding options | OpenAI, VoyageAI, Gemini, Ollama (local) |
| Vector store options | Milvus (Docker) or Zilliz Cloud |
| License | MIT |
The hybrid search matters more than you might think. Pure vector search is great for "find me the authentication handler" but misses exact matches for where a specific variable is validated. BM25 catches those keyword hits. Together they beat either approach alone.
Incremental Indexing
Once the initial index is built, only changed files get re-embedded. The project uses Merkle trees to track file hashes, so subsequent indexing runs are fast and cheap. This matters for real workflows -- re-indexing a 50,000-file monorepo from scratch is not something you want to do on every edit.
Configuration
Setting it up takes about two minutes:
claude mcp add claude-context \
-e OPENAI_API_KEY=sk-your-key \
-e MILVUS_ADDRESS=your-endpoint \
-e MILVUS_TOKEN=your-token \
-- npx @zilliz/claude-context-mcp@latest
Then in Claude Code:
Index this codebase
Check the indexing status
Find functions that handle user authentication
For the self-hosted path, you run Milvus via Docker and use Ollama for local embeddings. Fully air-gapped, no cloud bills.
Honest Limitations
The project is not zero-dependency. You need a vector database and an embedding API key. For cloud users that means two bills: Zilliz Cloud plus OpenAI -- on top of Claude Code. The self-hosted path (Milvus via Docker) removes the vector DB cost but adds operations overhead. There is no SQLite-mode yet.
The initial index takes several minutes for large repos and can cost a few dollars in embedding API calls. After that, Merkle-tree-based incremental indexing means only changed files get re-embedded, so ongoing costs are minimal.
Language support is good for TypeScript, Python, Go, Java, and Rust, all covered via tree-sitter parsers parsers. Less common languages fall back to character-based splitting, which means you lose the AST-aware chunking benefit.
There is no built-in cross-encoder re-ranker. The top-5 results come from hybrid search, but nothing re-orders them for relevance. A re-ranker would help if the agent frequently pulls the wrong chunk first.
A known state-sync bug: sometimes the index completes but search_code fails with "codebase not indexed" due to Milvus read-write synchronization delays. The workaround is to wait a few seconds for consistency.
Community Timeline
The trajectory tells the story:
"Claude Context is just a semantic code search plugin that fills the gap of missing search functionality in Claude Code." -- r/ClaudeAI
"If you have been frustrated with Claude Code or Cursor losing the plot in a 200-file repo, Claude Context is the most legitimate fix that has emerged from the MCP ecosystem this year." -- andrew.ooo review
There is also a healthy ecosystem of alternatives. The local-only fork uses EmbeddingGemma + FAISS for a fully air-gapped setup. Users who prefer no cloud dependency can run that instead, trading away the 40% token savings benchmark for full privacy.
So What
The MCP ecosystem hit 97 million monthly downloads this year for a reason. The pattern of one AI agent, one codebase, one retrieval mechanism is being replaced by interchangeable parts -- you pick the agent, you pick the vector DB, you pick the embedding model. Claude Context is the retrieval piece done right.
What makes it worth paying attention to is not the 40% token savings (though that is real). It is that the project is a genuine shift in how AI agents interact with code. The dump-and-pray approach is dying. Retrieval-augmented coding is becoming the default, and tools like Claude Context are the infrastructure that makes it work.
The honest question is whether you need it. If your codebase fits in Claude Code's 1M-token window and you are not watching your token budget, you probably do not. But if you have ever watched an agent spend $2 reading irrelevant files before it even starts working, you know exactly why this repo hit #1 today.