Last week, NVIDIA's research arm released something that feels more like a declaration of intent than just another open-source project: a compiler that lets you write GPU kernels in standard Rust, compile them directly to PTX, and skip C++ entirely.
cuda-oxide v0.1.0 is alpha software — the docs literally say "expect bugs, incomplete features, and API breakage." But the signal is clear. NVIDIA invested in a custom rustc codegen backend, Pliron (a Rust-native MLIR alternative), and a three-tier memory safety model for GPU programming. They didn't slap a wrapper on CUDA. They rebuilt the compiler pipeline from the MIR layer down.
Architecture
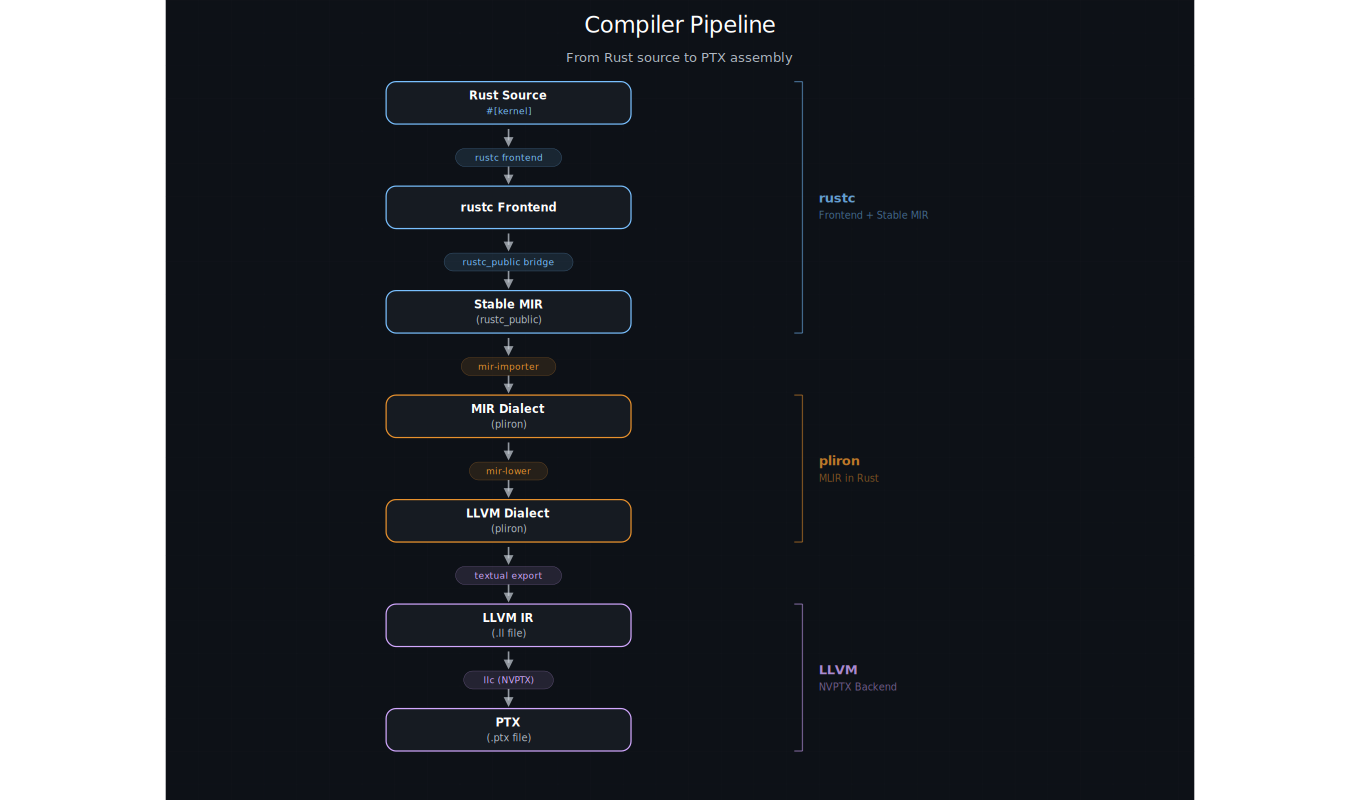
The compilation pipeline looks like this:
Rust Source → rustc Frontend → Stable MIR → Pliron IR → LLVM IR → PTX
At the center is a custom rustc codegen backend (rustc-codegen-cuda) that intercepts compilation via the -Z codegen-backend flag. When it sees a function with the #[kernel] proc macro, it renames it to cuda_oxide_kernel_<hash>_<name>, does a BFS traversal of the device call graph, and ships device code through the cuda-oxide pipeline while delegating host code to the standard LLVM backend.
The Pliron bet is the interesting part. Instead of depending on C++ MLIR with its gigabytes of build artifacts and TableGen DSLs, NVIDIA built Pliron — a pure-Rust MLIR-inspired IR framework. It defines three custom dialects:
| Dialect | Purpose |
|---|---|
| dialect-mir | Rust semantics (enums, structs, slices, address spaces) |
| dialect-llvm | LLVM IR operations (1:1 mapping) |
| dialect-nvvm | NVIDIA GPU intrinsics (tid, barriers, TMA, WGMMA) |
The Stable MIR bridge uses Rust's official versioned API (rustc_public) to convert internal MIR to a stable format, which means it won't break every time nightly updates. JumpThreading is explicitly disabled for device code to prevent the optimizer from breaking GPU barrier semantics.
Safety Model
cuda-oxide's safety model is the most thoughtful part of the design. It has three tiers:
Tier 1 — Safe by construction. The DisjointSlice<T> type requires a matching ThreadIndex witness to access elements. This witness is generated by hardware registers and cannot be cloned, sent, or shared. If your kernel compiles, data races on that buffer are impossible by construction.
#[kernel]
pub fn scale(input: &[f32], factor: f32, mut out: DisjointSlice<f32>) {
let idx = thread::index_1d();
if let Some(elem) = out.get_mut(idx) {
*elem = input[idx.get()] * factor;
}
}
Tier 2 — Scoped unsafe for thread cooperation (shared memory, warp shuffles, atomics). No different from writing unsafe in regular Rust.
Tier 3 — Raw hardware for performance engineers building libraries like CUTLASS. TMA, tensor cores, cluster-level communication. The unsafe escape hatch exists when you need it.
Competitor Comparison
cuda-oxide enters a crowded field of Rust-to-GPU projects:
| Project | Approach | Target | Philosophy |
|---|---|---|---|
| cuda-oxide | rustc codegen backend | NVIDIA PTX | Bring CUDA into Rust — SIMT kernel authoring |
| Rust-GPU | rustc → SPIR-V | Vulkan/Metal/DX | Graphics shaders via SPIR-V |
| rust-cuda | rustc → NVVM IR | NVIDIA PTX | Rust ergonomics on GPUs |
| CubeCL | Embedded DSL + JIT | CUDA/ROCm/WGPU | Cross-vendor compute |
| std::offload | LLVM offload | NVIDIA/AMD/Intel | Implicit CPU loop offload |
The key distinction is design center. rust-cuda says "bring Rust to NVIDIA GPUs" — async/await, standard library on-device. cuda-oxide says "bring CUDA into Rust" — kernel authoring, device intrinsics, the SIMT execution model expressed natively. The teams are coordinating, not competing.
Performance
The gemm_sol example hits 868 TFLOPS on an NVIDIA B200, which is about 58% of hand-tuned cuBLAS. For an alpha compiler running kernels written in idiomatic Rust, that's surprisingly competitive. Expect that gap to narrow as the compiler matures.
Community Reaction
Reddit r/linux: "One of the more interesting Rust/GPU developments in a while because it hints at NVIDIA taking Rust seriously."
r/rust (337 upvotes): A VectorWare engineer commented they've been giving feedback and tweaking this with NVIDIA. The Lobsters crowd appreciated that kernel launches avoid unsafe entirely.
Some skepticism too — the documentation has an AI-generated feel in places, and v0.1.0 requires Linux only, Rust nightly pinned to a specific date, LLVM 21+, and CUDA Toolkit 12.x. This isn't something you install on a whim.
So What
Three things make this worth paying attention to.
First, NVIDIA is signal-investing in Rust. This isn't a community side project. It's NVlabs with a full custom codegen backend. The Rust blog simultaneously announced raising the nvptx64 baseline to PTX ISA 7.0. The coordinate feels deliberate.
Second, the safety model is real engineering, not marketing. The DisjointSlice + ThreadIndex pattern eliminates an entire class of GPU data races at compile time. If you've ever debugged a CUDA kernel that corrupts memory nondeterministically, you know why this matters.
Third, Pliron replaces C++ MLIR in the GPU compiler stack. That's a bet on Rust-native tooling that extends beyond this project. If Pliron works, it changes how we think about building compiler infrastructure — no CMake, no TableGen, no gigabytes of LLVM headers. Just cargo build.
The catch is the same as always: alpha software, Linux-only, bleeding-edge toolchain requirements. But the foundation is sound, and NVIDIA has a track record of taking experimental compiler projects to production. If you write GPU code and care about memory safety, this is the most interesting thing that happened this month.
Sources
- GitHub: https://github.com/NVlabs/cuda-oxide
- Architecture docs: https://nvlabs.github.io/cuda-oxide/compiler/architecture-overview.html
- Safety model: https://nvlabs.github.io/cuda-oxide/gpu-safety/the-safety-model.html
- Reddit r/rust: https://www.reddit.com/r/rust/comments/1t7a5s7/nvidia_releases_cudaoxide_01_for_experimental/
- Reddit r/linux: https://www.reddit.com/r/linux/comments/1t7a52k/nvidia_releases_cudaoxide_01_for_experimental/
- Phoronix: https://www.phoronix.com/news/NVIDIA-CUDA-Oxide-0.1
- MarkTechPost: https://www.marktechpost.com/2026/05/09/nvidia-ai-just-released-cuda-oxide-an-experimental-rust-to-cuda-compiler-backend-that-compiles-simt-gpu-kernels-directly-to-ptx/
- Ecosystem comparison: https://nvlabs.github.io/cuda-oxide/appendix/ecosystem.html
- Hacker News: https://news.ycombinator.com/item?id=48055332
- Rust blog nvptx update: https://blog.rust-lang.org/2026/05/01/nvptx-baseline-update/