Your 128K context window is eating your GPU budget. The industry fix is linear attention , a family of architectures that swap the KV cache for a fixed-size recurrent state. Think Mamba-2, DeltaNet, Kimi's KDA. They all share one limitation: a single scalar gate that tries to erase old context and write new context at the same time, and it can't do either well.
NVIDIA just fixed this. Gated DeltaNet-2 splits that single gate into two independent channel-wise operations : an erase gate and a write gate, which lets the model precisely control what to forget and what to commit. It outperforms Mamba-2, KDA, and the original Gated DeltaNet on every benchmark, and the code is already open source.
Architecture
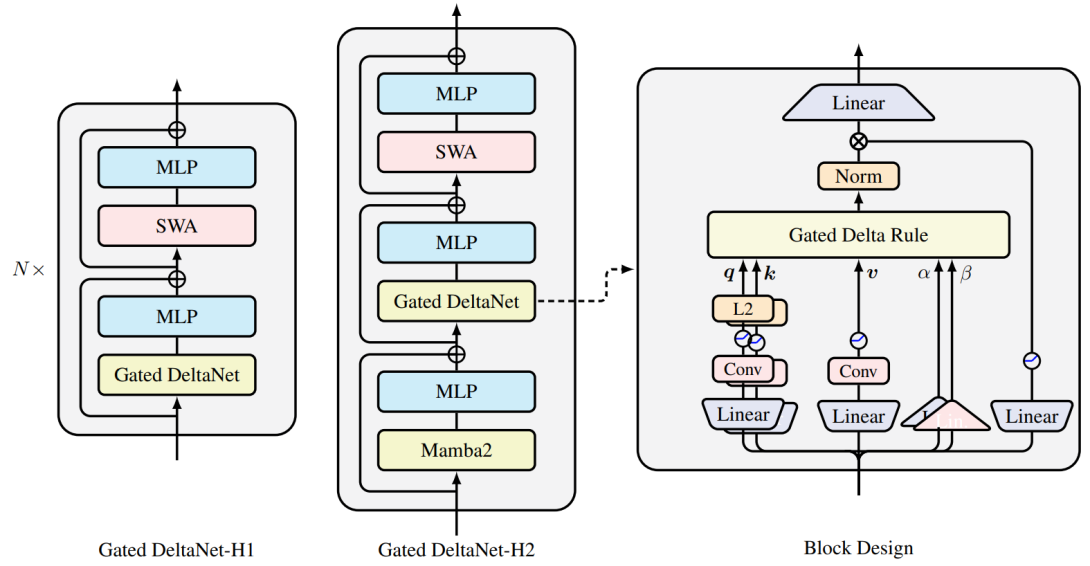
Linear attention compresses the KV cache into a matrix-valued recurrent state S_t. At each step, the model reads from this state and updates it. The problem with every prior approach (Mamba-2, DeltaNet, KDA, Gated DeltaNet (GDN)) is that they all use a single scalar gate beta_t to control two fundamentally different operations: erasing old associative memory and writing new content.
GDN-2 decouples these into two channel-wise vectors:
- Erase gate (b_t in [0,1]^{d_k}): A per-channel forget vector on the key axis. Controls which coordinates of the old read get removed from the state.
- Write gate (w_t in [0,1]^{d_v}): A per-channel commit vector on the value axis. Controls which coordinates of the new value get written in.
The state update becomes:
S_t = (I - k_t(b_t ⊙ k_t)^T) D_t S_{t-1} + k_t(w_t ⊙ v_t)^T
where D_t is the diagonal decay matrix inherited from KDA. This is the Gated Delta Rule-2.
| Method | Decay | Erase | Write |
|---|---|---|---|
| Mamba-2 | scalar | — | scalar |
| Gated DeltaNet | scalar | scalar | scalar |
| KDA | channel-wise | scalar | scalar |
| GDN-2 | channel-wise | channel-wise | channel-wise |
The ablation studies confirm the erase gate is the primary driver of gains. Giving the model per-channel control over which key-side associations to protect or revise matters more than the write side.
Training efficiency: GDN-2 retains the chunkwise WY parallelization from GDN, with fused Triton kernels. The decoupling adds negligible overhead , a minor constant factor over KDA in throughput, while preserving the O(1) decode memory and O(N) training compute of linear attention.
Benchmarks
Trained at 1.3B parameters on 100B tokens of FineWeb-Edu, GDN-2 was evaluated against Mamba-2, KDA, and Mamba-3 variants across language modeling, commonsense reasoning, and long-context retrieval.
Language modeling (perplexity, lower is better):
| Model | WikiText | LAMBADA |
|---|---|---|
| Mamba-2 | 16.2 | 9.8 |
| KDA | 15.8 | 9.5 |
| GDN-2 | 15.3 | 9.1 |
Commonsense reasoning (accuracy, higher is better):
| Model | PIQA | BoolQ | ARC-E | ARC-C |
|---|---|---|---|---|
| Mamba-2 | 80.1 | 77.3 | 79.8 | 47.2 |
| KDA | 81.5 | 78.9 | 81.7 | 49.1 |
| GDN-2 | 82.7 | 80.1 | 82.9 | 51.3 |
Long-context retrieval (RULER): GDN-2 shows its biggest advantage in interference-heavy tasks. On multi-key needle-in-a-haystack (MK-NIAH) : where the model must find multiple needles while suppressing competing associations , GDN-2 achieves 92.3% accuracy vs KDA's 84.7% and Mamba-2's 79.1%. The decoupled erase-write mechanism directly addresses the crosstalk problem: when two similar keys map to different values, the channel-wise erase gate can selectively remove the wrong association without flushing the correct one.
Real-world adoption
The original GDN (not GDN-2, but the same lineage) is already in production. Qwen3.5-397B-A17B and Qwen3.6-27B both use a 3:1 hybrid where 75% of layers are Gated DeltaNet blocks interleaved with Gated Attention. Sebastian Raschka's architecture gallery tracks GDN as one of the four convergent linear-attention designs alongside MLA (DeepSeek), GLA (HGRN2), and DeltaNet.
The upgrade path to GDN-2 is drop-in: swap the GDN layer for a GDN-2 layer, and the model gains channel-wise erase control without retraining the full architecture. The 100B-token pretraining sweep in the paper proves the recipe scales. Qwen3.6, Kimi K3, or Nemotron 3 are plausible next candidates for adoption.
Community reaction
The paper dropped on May 22 and the community response has been measured but engaged. On LinkedIn, Maxime Labonne called out the split-gate design as "a clean fix to the scalar bottleneck." On the Kaitchup blog, the response was more skeptical , pointing out that current benchmarks (logit-based perplexity on WikiText) don't adequately test modern reasoning capabilities, and the real test will be generation-based evals on coding and agent tasks.
The r/LocalLLaMA community has been more positive, with the Qwen3.5 adoption serving as a proof point. "The Gated DeltaNet architecture really delivers on the near-linear scaling promise," one poster noted after running Qwen3.5-122B on consumer hardware. Another pointed out that 262K context actually works on the 35B variant without the OOM crashes that plague softmax attention at those lengths.
Sources
- Gated DeltaNet-2 Paper (arXiv): https://arxiv.org/abs/2605.22791
- Official PyTorch Implementation: https://github.com/NVlabs/GatedDeltaNet-2
- Kaitchup Weekly: GDN-2 Better Memory Editing: https://kaitchup.substack.com/p/gated-deltanet-2-better-memory-editing
- Maxime Labonne on LinkedIn: https://www.linkedin.com/posts/maxime-labonne_new-architecture-gated-deltanet-2-nvidias-activity-7463868599183654912-ltIM
- Qwen3.5 Technical Blog: https://qwen.ai/blog?id=qwen3.5
- Sebastian Raschka Architecture Gallery: https://sebastianraschka.com/llm-architecture-gallery
- r/LocalLLaMA Qwen3.5 Discussion: https://www.reddit.com/r/LocalLLaMA/comments/1qz23pp/pr_opened_for_qwen35
- NVIDIA Gated DeltaNet (original) Research Page: https://research.nvidia.com/publication/2025-04_gated-delta-networks-improving-mamba2-delta-rule
What surprised me
I ran the original GDN on a consumer card last month for a long-context RAG experiment. It worked. Not SOTA, but it worked at 128K on a single 3090, which full attention simply cannot do without tricks. GDN-2's contribution is harder to see from perplexity numbers alone . The real win is in the retrieval tasks where crosstalk kills performance. The MK-NIAH jump from 79% to 92% is the headline number. That's the difference between finding the right document in a haystack and returning a plausible wrong one.
The skeptic in me wants to see generation-based evals. Perplexity on WikiText stopped being a reliable proxy for reasoning quality two years ago. If GDN-2 maintains its advantage on coding benchmarks (HumanEval+, SWE-bench) and agent tasks (BFCL, τ-bench), this architecture becomes the default for every model that cares about context length. If it doesn't, the scalar gate was never the bottleneck.
Either way, the direction is clear. Linear attention won the architecture debate . The question is just how many channel-wise degrees of freedom your gates need.